Better Bayesian Workflows with InferenceData and Xarray
Wednesday, May 10th, 2023 (about 1 year ago)
TLDR: The Xarray Dataset provides is the core of the arviz.InferenceData object. ArviZ InferenceData simplifies the Bayesian workflow, facilitates reproducibility, and enables interoperability between different Probabilistic Programming languages.
1# Load the saved results of a bayesian analysis from disk 2import arviz as az 3 4data = az.load_arviz_data("non_centered_eight") 5data 6
The Life of a modern Bayesian#
The utility of az.InferenceData will not be very apparent unless we first talk about the life of a Modern Bayesian Statistician,
the Probabilistic Programming Language (PPL) Designer, and what things used to be like before az.InferenceData.
The Modern Bayesian Practitioner#
Like most modern statisticians, the Modern Bayesian Statistician uses a computer to perform their work. Many PPLs are available for this kind of work, such as Stan, PyMC, Tensorflow Probability, NumPyro etc.
With a probabilistic programming language in hand, the Bayesian then follows the "Bayesian workflow" below, performing each of the various steps as part of their analysis.
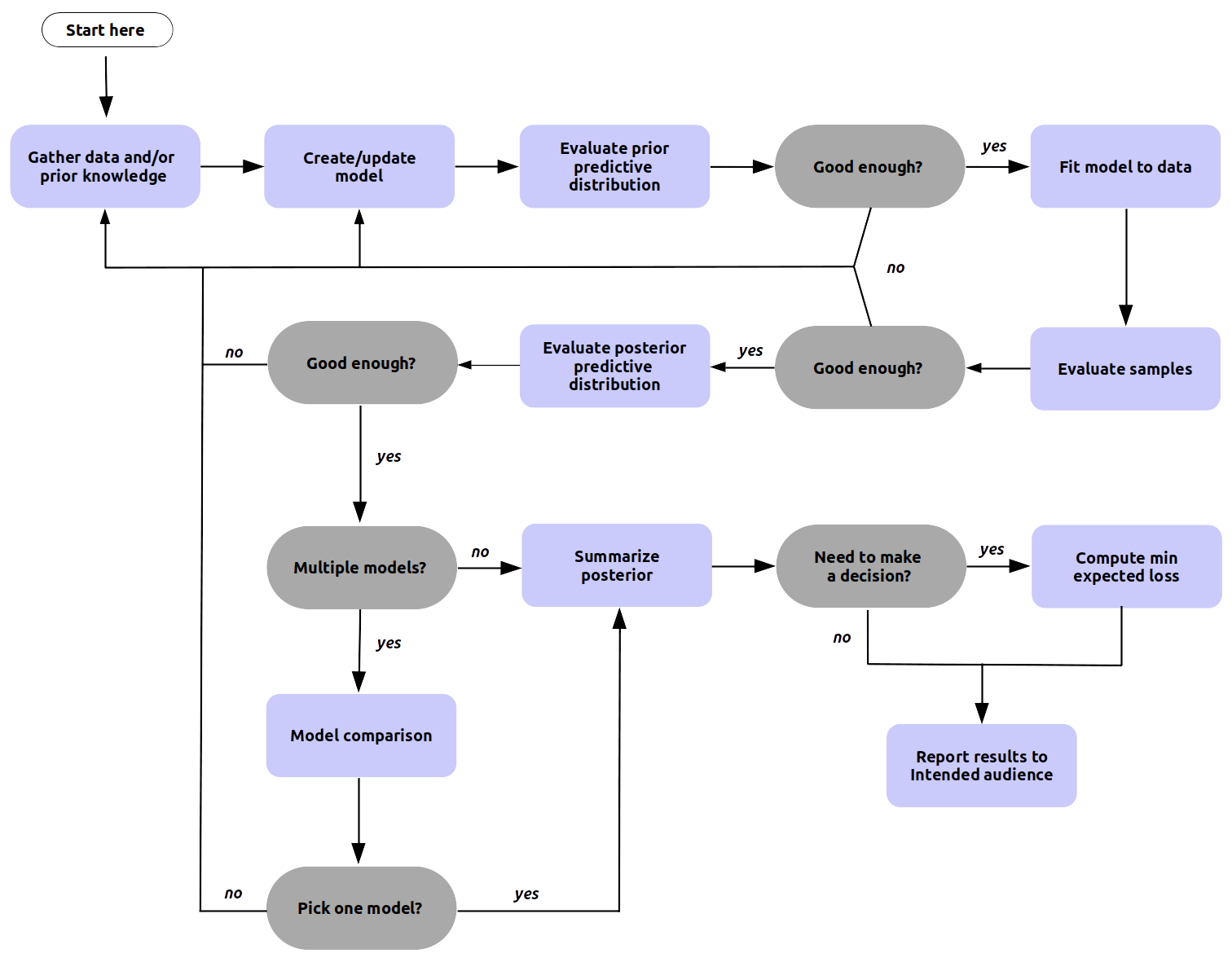
At each of these steps the PPLs generate many arrays, and not only single dimension arrays, but multi dimensional arrays. The prior predictive distribution, the posterior distribution, the posterior predictive distribution, the log likelihood, and even the input data are all numerical quantities that need to be captured and ordered to facilitate analysis.
Often these arrays need to be passed to specialized functions in order to check for Markov Chain Monte Carlo (MCMC) convergence, model comparison, or getting summaries from the target distribution.
And once the individual statistician has completed their work, they may either want to save it to disk, or share it with a colleague.
The Modern PPL designer#
Now consider a PPL designer. PPL designers typically want to focus on model building and inference: graph representation, samplers, symbolic differentiation speed and stability. However for their PPL to be useful they must ensure that users have easy access to diagnostics, visualizations, and model criticism tools. Suddenly the scope of their codebase grows, and duplicative functionality now exists across the open source Bayesian ecosystem.
Life before az.InferenceData#
Before az.InferenceData there wasn't a consistent object or method both for the user or for the PPL library maintainers.
Things like posteriors, prior predictives, observed data, and sampler stats could be stored in their own ways.
For example one PPL may store their modeling outputs in a dictionary, other may have used plain NumPy arrays, a third had its own custom class.
And that's even before considering the shapes and indices of the array.
This all meant
- Each PPL designer would have to implement their own data objects and would have to solve lots problems like how to serialize data to disk.
- All adjacent workflow libraries would only work with a subset of these objects, or would require users to restructure data each time.
- The APIs and interfaces for all of these were inconsistent making life challenging for end user. Users of different PPLs would be isolated in completely different ecosystems, even when the PPLs share the same general programming language.
How az.InferenceData works and its implementation#
az.InferenceData is an object that stores (nearly) all the outputs of Bayesian Modeling in a consistent manner.
Under the hood az.InferenceData is largely a collection of Xarray objects, with some utility functions built in as well.
Xarray was the natural choice, because storing indexes, and performing calculations
over multidimensional outputs are routine tasks for computational Bayesian modelers.
Named dimensions let us directly interact with the dimensions of interest, such as the quantities being studied.
Importantly they also remove implicit assumptions of which dimension represents chains and draws.
These dimensions are necessary for sampling and some diagnostics,
but are not so interesting when trying to perform inference and draw conclusions about the question at hand.
Often in Bayesian analysis we tend to reduce multidimensional arrays into lesser multidimensional arrays, for instance taking the mean across a distribution while leaving the other dimensions untouched. Xarray named dimensions also let us do this in a readable and repeatable way agnostic of PPL or model construction.
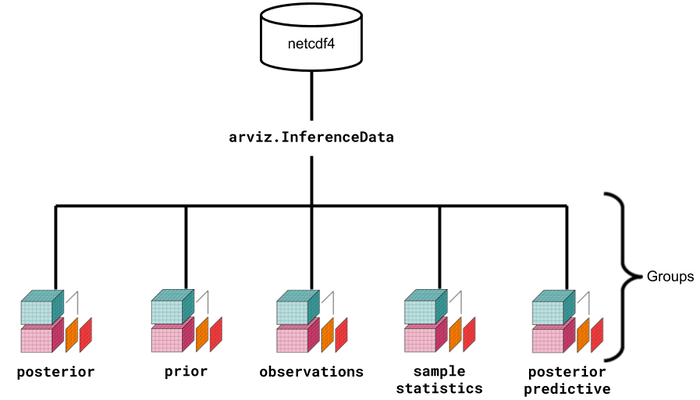
How this enables ArviZ#
With a consistent object that represents the outputs of PPLs, it became possible to develop ArviZ, a unified library for exploratory analysis of Bayesian models. Now it does not matter which PPL someone decides to use, as long as they follow the InferenceData specification ArviZ will know "what to do". This enables PPL designer to focus on the core of inference, and also ensures Bayesian Practitioners don't need to relearn the entire toolbox if they decide to switch PPLs.
The benefit of Xarray#
Xarray, in turn, simplifies the lives of the ArviZ developers because we do not need to focus too much on the data storage object, and instead, we can focus on the statistical computations. Of the key features of Xarray we directly utilize
- Interoperability
- Operations over named dimensions
- Value selection by label
- Vectorized operations
- Flexible and Extensible I/O backend API
Xarray Einstats#
The ArviZ project also maintains xarray-einstats, which provides label-aware wrappers for the following functionalities:
- Linear algebra (wrapping
numpy.linalg) - Statistical computations like summary statistics, random sampling, or working with distributions (wrapping
scipy.stats) - Reduce and rearrange operations (wrapping
einops)
Conclusion#
Xarray enables neat functionality, standardization, and simplification for Bayesian users. If you're a Bayesian practitioner we invite you to use ArviZ, and Xarray by extension, to see how easy things are. If you're a library developer for anything that uses numerical, consider how Xarray could help your users. We're quite thrilled with the capabilities of Xarray today and are excited to see what's to come in the future!